Modéliser les licornes pour mieux prédire les espèces réelles
Ceci est le repost d'un article que nous avons écrit pour le blog d'Ecography
En 1990, Stuart H. Hurlbert a analysé la “Distribution Spatiale de la Licorne de Montagne”. La Licorne de Montagne était une espèce rare, qui n'avait était décrite que très récemment, et Hurlbert était le premier à signaler des données sur cette espèce spéciale. Ses données montraient que les populations de licornes avaient leurs distributions d'abondance très bizarres et hétérogènes. Il les a donc analysé avec les méthodes les plus reconnues à l'époque, à savoir le ratio "moyenne:variance". En effet, on admettait à l'époque que lorsque ce ratio variance:moyenne était égal à 1, alors les distributions d'abondances suivaient une loi de Poisson. Pourtant, de manière surprenante, Hurlbert montra qu'aucune de ses populations de licorne ne suivait une loi de Poisson, mais toutes avaient un ratio variance:moyenne égal à un, prouvant alors que le ratio variance:moyenne était inutile comme mesure de l'agrégation des populations.
Stuart H. Hurlbert a eu l'idée brillante de simuler des données pour invalider une croyance de longue date en écologie statistique. L'écologie est une science construite sur la base de données échantillonnées sur le terrain, à partir desquelles les écologues font des hypothèses qu'ils testent avec des méthodes statistiques. Cependant, toutes les méthodes statistiques ne sont pas complètement comprises, ou correctement appliquées par les écologues. Par conséquent, les modèles ne modélisent pas toujours ce qu'on croit qu'ils modélisent, ou leurs résultats ne signifient pas toujours ce qu'on croit qu'ils signifient. Dans de tels cas, les données simulées peuvent aider à valider ou invalider nos hypothèses sur les modèles.
Cette approche générale de simulation serait probablement appelée l'approche de "l'Ecologiste Virtuel" en écologie moderne (Zurell et al. 2010). Plusieurs domaines de l'écologie (biogéographie, écologie des changements climatiques, biologie des invasions, biologie de la conservation) utilisent intensément des modèles pour prédire les répartitions d'espèces. Ces modèles, appelés modèles de prédiction de répartition d'espèces (SDMs) (également appelés modèles de niche écologiques ou modèles d'habitats) relient statistiquement des données d'occurrence d'espèces avec des variables environnementales pour prédire les répartitions potentielles d'espèces. L'essor des SDMs dans la littérature a abouti au développement d'une pléthore d'outils, méthodes et protocoles. Savoir quelles approches modélisent le mieux les répartitions d'espèces est un challenge que de nombreux écologues ont abordé avec des données d'espèces échantillonnées. Cependant, les données échantillonnées souffrent de nombreux biais (e.g., données incomplètes, biais spatial, erreurs d'identifications, détection inadéquate) qui empêchent la généralisation de ces tentatives de validation. Par conséquent, les écologues ont décidé de commencer à modéliser des licornes dans la dernière décénie, et ont commencé à simuler des espèces virtuelles afin de valider leurs hypothèses sur les SDMs, tester leurs performances, ainsi que les effets de différents biais.
Ainsi, les espèces virtuelles deviennent un outil commun dans la littérature sur les SDMs. Cependant, modéliser les licornes n'est pas une tâche aisée, car cela requière d'importantes compétences de programmation, et il n'existait pas de logiciel ou package complet et "user-friendly" jusque récemment. En outre, si elles n'étaient pas planifiés correctement, les licornes simulées pouvaient également mener à de mauvaises conclusions. Meynard et Kaplan (2013) ont par exemple montré qu'une simulation inadéquate pouvait mener à une forte surestimation de la précision des SDMs, et Moudrý (2015) a creusé encore plus profondément dans les problèmes liées à l'utilisation de simulations inappropriées. Par conséquent, nous avons décidé d'aider la communauté écologique à simuler adéquatement les licornes, en proposant un package R complet et user-friendly nommé "virtualspecies". virtualspecies combine les approches méthodologiques existantes dans un framework complet, avec l'objectif de générer des répartitions d'espèces virtuelles avec un réalisme écologique accru.
Ce package est décrit dans notre article récent Leroy B., Meynard, C.N., Bellard C. & Courchamp F. 2015. virtualspecies: an R package to generate virtual species distributions. Ecography. Il est disponible gratuitement, et un tutoriel complet est aussi disponible ici : http://borisleroy.com/en/virtualspecies/.
L'Anthropocène, ou les débuts sinistres de l'ère de l'Homme
On parle de plus en plus de l'anthropocène, dans et hors de la communauté scientifique. L'anthropocène, c'est un terme utilisé par les géologues pour désigner l'ère géologique dans laquelle nous vivons actuellement. Elle signifie plus ou moins "l'ère de l'Homme", c'est-à-dire l'ère dans laquelle on reconnait l'Homme comme une force géologique majeure, une force qui altère significativement et globalement la Terre.
Bien que ce terme soit de plus en plus utilisé, l'anthropocène n'est pas encore reconnue officiellement par les instances géologiques scientifiques comme une véritable ère géologique. En effet, pour être reconnue comme ère géologique elle doit satisfaire un certain nombre de critères, dont :
- Les changements à l'échelle globale doivent être détectables dans les matériaux stratigraphiques (roches, glaciers, sédiments marins)
- Un point de départ datable (qui marque également la fin de l'ère précédente) doit être identifié, tel qu'un changement soudain et marqué dans la composition chimique des strates géologiques. Par exemple, pour dater le passage du crétacé au paléogène, les géologues utilisent le pic d'iridium daté d'il y a 66 millions d'années, qui nous indique l'impact d'un météore sur la Terre, lui-même localisé en Tunisie.
Ce point de départ, en plus d'être précis et global, doit être accompagné de marqueurs secondaires dans les strates montrant d'autres changements largement répandus sur la terre survenant en même temps, comme la composition chimique ou les changements de faune (extinctions par exemple).
- 1610 : cette date correspond à un minimum de CO2 observé dans l'atmosphère. Pourquoi parler de CO2 en 1610 ? Les émissions de CO2, ça n'est pas depuis le 19e siècle seulement ? Hé bien non, car les humains déforestent depuis un petit moment déjà, pour faire de la place pour l'agriculture, ce qui a engendré une augmentation lente et progressive du taux de CO2 atmosphérique. Cependant, il y eut une diminution exceptionnelle du de 1550 à 1610. 1610 correspond en fait à la fin d'une période sordide : la découverte des Amériques par les Européens. Entre 1500 et 1600, les européens ont progressivement répandu guerres, épidémies, esclavagisme et famine chez les indigènes d'Amérique, ce qui a abouti à la disparition de 50 à 60 millions de personnes (en 1492 : 54-61 millions d'habitants estimés aux Amériques ; en 1650 : 6 millions). Ce chiffre sinistre correspond à près de dix fois celui de la seconde guerre mondiale. Ce génocide a induit la disparition de l'agriculture sur une bonne partie des Amériques, et en 100 ans les forêts se sont progressivement reconstituées, ce qui a inversé temporairement la tendance du carbone. On observe une diminution du taux de carbone atmosphérique jusqu'en 1610, à un taux minimum, avant que celui-ci ne recommence à croître.
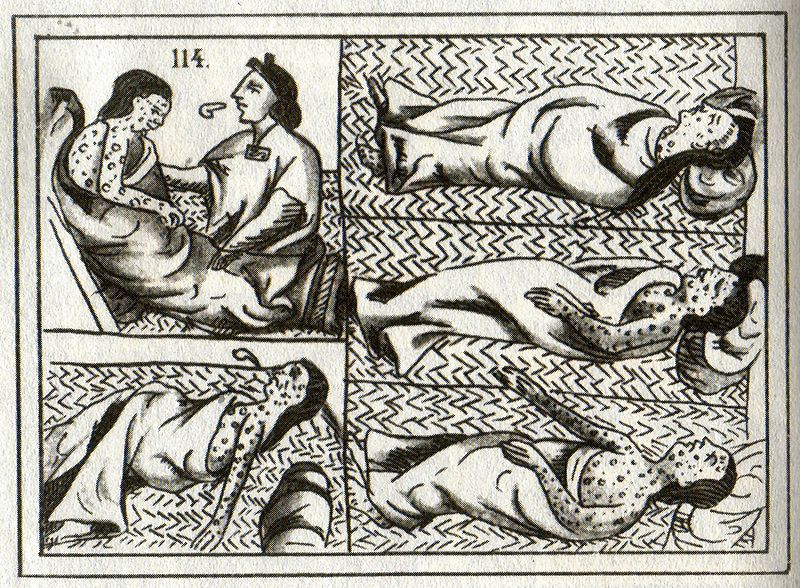
- 1964 : à cette date correspond un maximum de carbone 14 dans l'atmosphère. Le carbone 14 est la version radioactive du carbone, et son pic en 1964, vous l'avez sûrement deviné, est dû aux multiples développements et essais des armes atomiques par plusieurs nations dans le monde (donc pas seulement les deux bombes larguées au Japon). Ce pic s'accompagne de nombreux autres marqueurs radioactifs résultant des tests de bombes atomiques à l'échelle globale. Il marque également les débuts de la "Grande Accélération" dans les changements majeurs induits par l'homme à l'échelle globale, à commencer par l'augmentation exponentielle des émissions de CO2.

Les auteurs de l'article soulignent que "l'évènement ou la date choisie comme le commencement de l'Anthropocène affectera les histoires que les gens construisent sur les développement des sociétés humaines." Quelle que soit la date choisie entre 1610 et 1964, le symbole est sinistre : guerre, terreur et violence. Que cela soit un rappel embarrassant de ce dont nos sociétés sont capables pour guider nos choix sociétaux futurs.
Réduire le nombre d'ampoules ou réduire leur consommation ?
La dégradation de l'environnement s'accélère à mesure que la population humaine s'accroît, et les efforts actuels n'infléchissent pas la tendance des indicateurs, au contraire. Intuitivement, on peut considérer que réduire la taille de la population humaine, en réduisant la fertilité, est l'une des choses les plus urgentes à faire pour assurer notre avenir sur cette planète. C'est déjà en partie le cas dans les pays développés, qui disposent de moyens de contraception, ou de manière plus drastique en Chine, avec la loi un seul enfant. Cependant, la plupart des populations dans les pays en voie de développement n'ont pas accès aux moyens de contraception qui limiteraient les naissances non voulues, et les efforts en ce sens sont freinés, notamment par des considérations religieuses.
Il en va pourtant de l'avenir de l'humanité : nous sommes actuellement plus de sept milliards sur la Terre, et en 2100 nous serons entre 9.6 et 12.3 milliards (par comparaison, nous étions 1.6 milliards en 1900). Objectivement, la réduction de la taille de la population peut donc apparaître comme l'objectif n°1 pour limiter la destruction de l'environnement. Est-ce correct ? Est-ce faisable ?
Ce sont les questions auxquels deux écologues (Corey Bradshaw et Barry Brook) ont tenté de répondre en simulant l'évolution de la population en testant différents scénarios : réduction de la fertilité jusqu'à deux enfants par femme pour 2100, jusqu'à un enfant par femme pour 2100, ou carrément en 2045, suppression de toutes les naissances non voulues (~16% des naissances), pandémies, guerre mondiale aux pertes proportionnellement identiques à la seconde guerre mondiale.
Leurs prédictions indiquent qu'étant donné l'élan actuel qu'a la démographie humaine, il est impossible de limiter significativement la taille de la population d'ici à 2100 d'après les scénarios "réalistes" (estimations > 9 milliards). Les scénarios moins réalistes ou catastrophiques ne sont pas des solutions miracles non plus. La politique d'un enfant par famille en 2100 aboutirait à 7 milliards d'êtres humains sur la terre en 2100 (soit autant qu'aujourd'hui). Même des scénarios catastrophes type seconde guerre mondiale aboutirait à 10 milliards d'humains en 2100, ou un évènement de mortalité de masse type pandémie emportant 2 milliards d'humains en 5 ans aboutirait à > 8 milliards d'humains. Supprimer toutes les naissances non voulues aboutirait à >7 milliards en 2100.

Ces résultats montrent simplement que la réduction de la taille seule n'est pas une solution miracle. Attention, ils n'indiquent pas qu'il ne faut pas progressivement réduire la fertilité de la population humaine : une réduction est faisable est aboutirait à des centaines de millions de bouches en moins à nourrir pour 2100 ; et à mon avis des centaines de millions souffrant moins des conséquences de leurs générations précédentes.
J'ai le sentiment d'être face à une situation pire encore que le postulat de Khazzoom-Brookes. Ce postulat précise en résumé qu'une meilleure efficacité énergétique aboutit globalement à accroître la consommation énergétique. Une métaphore simple : les ampoules consomment moins ? Mettons des ampoules partout !
Pour contrer ce postulat, il faudrait empêcher d'augmenter le nombre d'ampoules, tout en réduisant leur consommation d'énergie. Si on ne peut pas empêcher d'augmenter le nombre d'ampoules, dans ce cas on doit réduire leur consommation d'énergie au minimum possible.
Pour l'espèce humaine, c'est exactement cette dernière situation. On sait désormais qu'il sera très difficile de limiter la démographie d'ici à 2100 ; donc il nous incombe à tous de réduire drastiquement notre consommation de ressources pour assurer la survie de notre espèce.
SDMs : Schrödinger Distribution Models
Tout le monde connait le chat de Schrödinger.
Ce fameux chat qui serait à la fois mort et vivant, tel que défini d'après un modèle quantique.
On peut s'amuser à faire l'analogie avec les prédictions d'impacts des changements climatiques sur les répartitions d'espèces. La plupart de ces prédictions ont été réalisées par le biais des modèles de prédictions de répartition (abrégés SDMs en anglais). Le problème, c'est que les SDMs sont des techniques assez incertaines.
Petite définition technique
Techniquement, les SDMs consistent à corréler l'occurrence d'une espèce (les lieux où elle a été observée) à des variables environnementales (par exemple le climat connu dans ces lieux). Cela nous permet de supposer la relation entre espèce et environnement, et ainsi d'extrapoler dans l'espace pour voir où l'environnement est favorable à la présence de l'espèce ; et dans le temps, par exemple pour prédire les impacts des changements climatiques sur l'espèce.
D'une part, il existe de nombreuses techniques différentes ("GLM", "GAM", "MaxEnt", "BRT", etc.) ; chacune avec leurs propres hypothèses sous-jacentes, et paramétrisations. Ces différentes techniques donnent souvent des résultats différents, parfois même divergents. De plus, il existe de nombreux protocoles : basés sur les données de présence-absence, de présence seulement avec échantillonnage de pseudo-absences (sous différentes modalités), de validation croisée, etc.
Il faut également bien choisir ses variables environnementales, pour qu'elles soient pertinentes. Quand on connait bien la biologie de l'espèce, ça peut être facile, mais quand ce n'est pas le cas, on essaye de les identifier par un protocole de sélection de variables. Différentes variables sélectionnées impliquent différents résultats.
A cela s'ajoute le fait que pour faire des projections dans le futur, il faut se baser sur des scénarios, qui sont donc incertains. Et pour chacun de ces scénarios, il y a de nombreux modèles climatiques, chacun tentant de représenter à sa manière le climat futur pour le scénario associé. Ils sont tous plus ou moins performants, chacun étant plus fort dans une région du globe que dans une autre. Comme prévu donc, différents modèles climatiques donnent des résultats différents pour un même scénario.
J'omets ici de parler des données d'occurrence de l'espèce que l'on cherche à modéliser : suivant leur quantité et qualité (enfin, plutôt leurs biais), les résultats seront également différents.
Comment choisir le bon modèle ?
On pourrait utiliser les techniques d'évaluation des modèles, pour tenter de trouver le meilleur modèle. Cependant, ces techniques permettent rarement de "réellement" évaluer les modèles (je ne m'étale pas dessus dans cet article, ce sera peut-être le sujet d'un future article). Ainsi, en général, les techniques d'évaluation ne permettent pas d'identifier les prédictions fiables ; elles permettent seulement d'évaluer les prédictions non fiables. En d'autres termes : une mauvaise évaluation d'un modèle signifie que le modèle est très certainement très mauvais ; par contre une bonne évaluation ne signifie pas que le modèle est bon.
Nous restent alors les approches de type modélisation d'ensembles (Ensemble Modelling), qui consistent à faire nos prédictions avec différentes techniques de modélisation, différents modèles climatiques, etc. puis de regarder la prédiction moyenne, ou médiane. Plusieurs travaux ont montré que cette prédiction moyenne ou médiane donnait de meilleurs résultats qu'une prédiction individuelle ; mais la véritable force de l'Ensemble Modelling est de montrer la variabilité des prédictions. Si toutes nos prédictions sont les mêmes, le résultat est bien plus fiable que lorsque les prédictions sont opposées !
Schrödinger Distribution Models
Cependant, si on ose regarder l'ensemble de nos prédictions, il n'est pas rare d'aboutir à des 'Schrödinger Distribution Models', avec la même espèce prédite pour à la fois s'éteindre (-100% à la taille de son aire de répartition) et se super-étendre (par exemple, +200% à la taille de son aire) !

Ces Schrödinger Distribution Models posent deux questions :
1. Peut-on faire confiance à une prédiction livrée sans incertitude ?
2. Comment utiliser des prédictions dignes de Schrödinger ?
1. Une prédiction sans incertitude est incertaine
Les SDMs sont donc incertains, d'autant plus dans le cas des projections futures. Pour cette raison, il m'apparait indispensable de donner une indication de l'incertitude du résultat lorsque l'on fait des prédictions. Interpréter sans incertitude relève de l'horoscope.Il faut de toute évidence présenter les résultats de différents scénarios de changement climatique, car ce sont différents futurs plausibles identifiés par le GIEC. Mais il faut également informer de la variabilité des prédictions en réalisant un 'ensemble model' par scénario, montrant toutes les prédictions possibles pour ce scénario.
Ci-dessous, un exemple tiré d'un article que l'on a récemment publié sur les araignées. A gauche, les prédictions moyennes issues de l'ensemble modelling fournies seules ; à droite, les prédictions moyenne fournies avec leurs incertitudes (intervalles représentant 95% des prédictions). L'expansion d'aire prédite dans le futur va donc de +0% à +125%, tandis que la contraction prédite va de -0% à -75%. On constate donc que si on se base sur la seule prédiction moyenne, cela revient à se passer de la majeure partie de l'information.
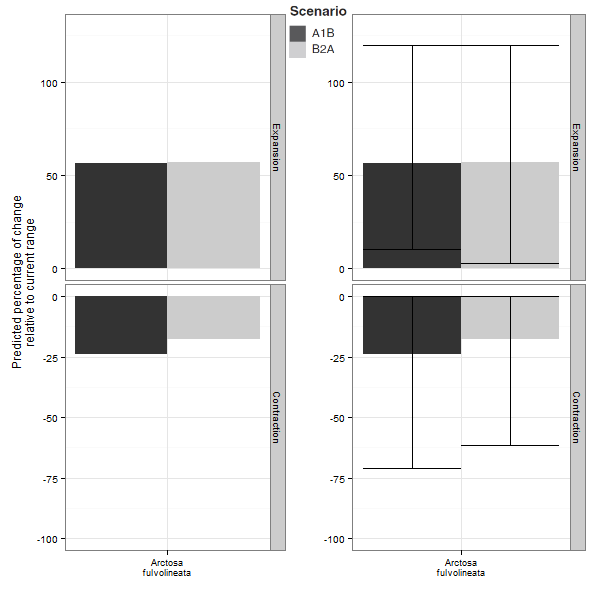
Dans le cas de l'utilisation d'une seule prédiction pour un scénario climatique, celle-ci devrait être solidement justifiée, sinon il devient possible de choisir la prédiction qui nous arrange le mieux, celle qui donne le résultat que l'on attendait...
2. Une prédiction incertaine peut donner des certitudes — ou comment utiliser des prédictions dignes de Schrödinger ?
D'une part, des modèles totalement en désaccord nous donnent la certitude de la piètre qualité des prédictions. Elle conduit à se poser des questions sur la qualité de la calibration, sur les raisons pour lesquelles les résultats des modèles ne convergent pas. On peut avoir affaire à une espèce dont la répartition est en réalité conditionnée par des facteurs trop difficiles à modéliser (par les SDMs), tels que des facteurs à des micro-échelles, des facteurs biotiques, etc.
D'autre part, selon la question posée, il est également possible d'exploiter des prédictions très divergentes en "s'extrayant" de l'incertitude issue des modèles. Kujala et al. (2013) proposent par exemple un cadre méthodologique robuste pour planifier des actions de conservation sur la base de prédictions incertaines. Pour résumer, le principe consiste à se concentrer sur les régions où les modèles sont d'accord, plutôt que celles où les modèles sont en désaccord.
Par exemple, il est possible de calculer une probabilité de présence "dépourvue d'incertitude", en soustrayant de la probabilité moyenne (de l'ensemble modelling) n fois l'écart-type des probas de présence issues de toutes les prédictions. Ce type d'approche est tiré des théories de décision face à des incertitudes sévères, et à mon avis il serait bénéfique qu'elles se généralisent dans le cadre des prédictions des impacts des changements globaux sur la biodiversité. C'est ce que nous avons fait sur les araignées pour identifier des populations à protéger dans le cadre d'un programme de conservation, malgré une incertitude élevée pour certaines espèces.
TL; DR
Les modèles de prédiction de répartition ont des incertitudes inhérentes qui peuvent être énormes dans le cadre de projections futures : ces incertitudes devraient toujours être évaluées pour interpréter correctement.
Ne croyez jamais une prédiction livrée sans indications d'incertitude...
Des méthodes existent pour pouvoir utiliser les SDMs malgré des incertitudes énormes, et devraient donc être (systématiquement ?) appliquées.
Nouveau poste, nouveau site, nouveaux projets... nouveau blog !
Jusqu'à présent ce site me servait principalement de CV en ligne, pour exposer mes recherches et, soyons francs, m'aider à trouver un travail fixe dans le monde impitoyable de la recherche.
Hé bien voilà ! C'est fait ! J'ai été recruté en tant que Maître de Conférences au Muséum National d'Histoire Naturelle, dans l'équipe Biodiversité et Macroécologie de l'UMR Biologie des Organismes et Ecosystèmes Aquatiques. J'ai décidé de profiter de ce changement majeur dans ma vie pour recréer mon site, et notamment de l'organiser autour d'un blog que je mettrai à jour régulièrement.

Ce blog sera centré autour d'une thématique commune à mes projets de recherche actuels et futurs, à savoir la prédiction des changements de biodiversité, notamment face aux changements globaux.
Je publierai deux grands types d'articles dans ce blog :
- des articles sur les recherches actuellement menées dans ce domaine, écrits de manière accessible à tous. Ils concerneront mes recherches ainsi que d'autres recherches importantes menées dans ce domaine.
- des articles sur les approches méthodologiques développées dans ce domaine, plutôt orientés vers un public initié. Cela signifie des articles techniques sur R, par exemple sur les modèles de prédiction de répartition. Ce sera l'occasion de fournir à tous des scripts pour des utilisations poussées, comme on me l'a conseillé à de nombreuses reprises...
Si vous êtes intéressés pour lire ce que je publie ici, n'hésitez pas à entrer votre mail (dans la colonne de droite) pour être notifié de nouveaux articles, ou d'utiliser les flux RSS (dans la colonne de droite aussi) pour votre lecteur RSS favori.
Invasions futures et changements climatiques
Les invasions biologiques représentent l’une des plus grandes menaces qui pèsent sur la biodiversité. L'Union internationale pour la conservation de la nature a défini « 100 espèces invasives parmi les pires à travers le monde ». Une équipe de chercheurs (CNRS / Université Paris-Sud / Université Joseph Fourier Grenoble 1 / Université de Rennes 1 / MNHN / Institute for Environmental Protection and Research, Rome / Netherlands Environmental Assessment Agency) vient de montrer que les changements climatiques et les changements d’occupation des terres peuvent conduire à un bouleversement important dans la distribution spatiale de ces espèces invasives d’ici à 2100 ! Cette étude vient d’être publiée le 4 septembre dans Global Change Biology.
Plus d'infos :
Et l'article en lui-même !
Bellard C., Thuiller W., Leroy B., Genovesi P., Bakkenes M., & Courchamp F. In press. Will climate change promote future invasions? Global Change Biology [lien]
-edit (25/09/2013)-
L'article bénéficie d'un coverage dans Nature !
Plots de corrélation dans R
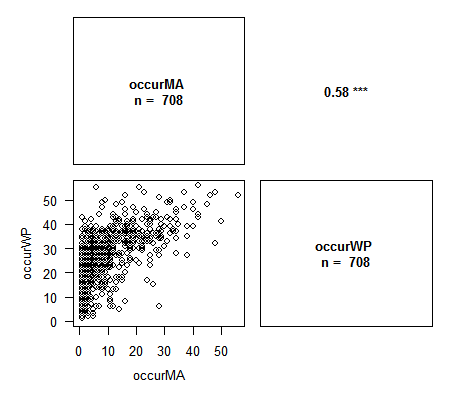
La version 1.2-1 du package Rarity vient de sortir, et cette version introduit une nouvelle fonction permettant de faire des « plots de corrélation ».
Ces plots de corrélation permettent d’analyser graphiquement et rapidement la corrélation entre deux ou plus variables avec une représentation synthétique.
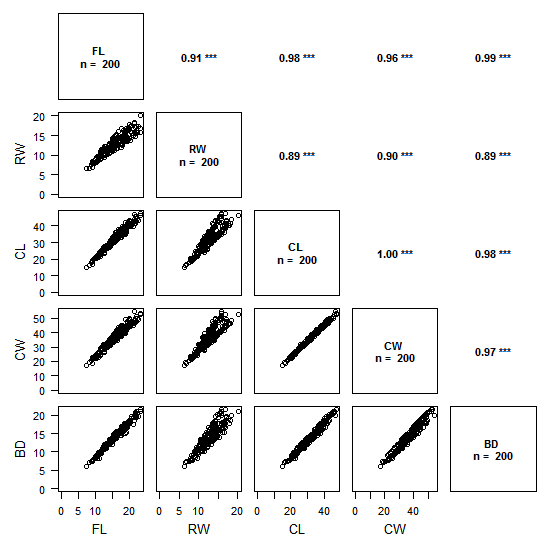
Ci-dessus un exemple avec des données de taille de crabes (package MASS).
Le graphique se décompose en deux :
- le triangle inférieur gauche présente les relations entre variables 2 à 2, de type « scatter plot »
- le triangle supérieur droit présente les valeurs de corrélations avec la méthode choisie (ci-dessus : Pearson) et le degré de significativité associé.
Le degré de significativité suit le code suivant :
p ≤ 0.001 : ‘***’
p ≤ 0.01 : ‘**’
p ≤ 0.05 : ‘*’
p ≤ 0.1 : ‘-’
La lecture se fait en croisant les variables sur le graphique comme dans la lecture d’un tableau de contingence : par exemple, le graphique tout en haut à gauche présente les valeurs de RW en fonction de FL, et en regard, de l’autre côté de la diagonale, on a la valeur du coefficient de corrélation de Pearson correspondante : 0.91, avec une significativité élevée (p < 0.001).
Pour créer cette fonction je me suis largement inspiré du graphique en Supporting Information de Kier et al. 2009 (page 3).
L’appel de la fonction est relativement simple, il faut simplement un data.frame avec les différentes variables en colonnes, préciser la méthode, et le reste est automatique. Deux méthodes sont disponibles :
- Pearson : dans ce cas les valeurs des variables sont directement affichées sur le graphique
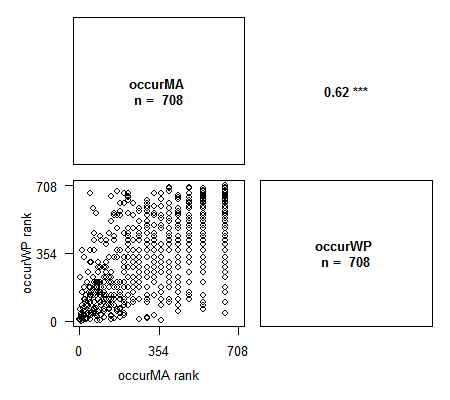
- Spearman ou Kendall : dans ce cas les rangs des variables sont affichées, car ces méthodes sont basées sur les rangs
Voici une série d'exemples simples à 2 variables (cette fonction sera surtout utile avec plus de 2 variables).
> library(Rarity) > data(spid.occ) # Exemple avec les occurrences des araignées du Massif Armoricain > corPlot(spid.occ, method = "pearson")> corPlot(spid.occ, method = "spearman")# Avec Spearman on a le graphique des rangs des variables. Cette méthode est particulièrement appropriée lors de l'étude de la congruence entre indices.
Les variables contenant des NA sont correctement gérées par la fonction. Plusieurs options pour ajuster le graphique sont disponibles : nombre de chiffres pour les valeurs de corrélation, labels des axes, traitement des NA, titre, et toutes les options graphiques habituelles pour changer le contenu des plots. N’hésitez pas à me faire des suggestions d’ajout !
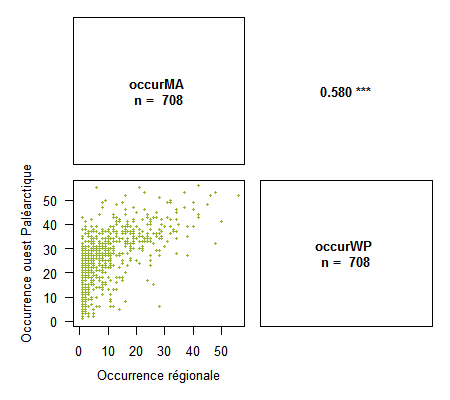
> corPlot(spid.occ, method = "pearson", pch = 16, cex = .5, digits = 3, xlab = c("Occurrence régionale", "Occurrence ouest Paléarctique"), ylab = c("Occurrence régionale", "Occurrence ouest Paléarctique"), col = "#94B62D")
{kind=link}
{kind=link}
{kind=link}
Merci à Ivailo Stoyanov pour ses conseils sur l’amélioration de cette fonction.
- edit-Corrigé et à jour sur le CRAN !
Un petit bug s’est glissé dans la version 1.2 du package et lorsque la méthode de Pearson est utilisée, le graphique partira toujours de 0. Ce bug a été corrigé et sera inclus dans la prochaine version du package !
En attendant la mise à jour sur le CRAN, voici la version corrigée : Rarity_1.2-1 (zip) ou Rarity_1.2-1.tar.gz (Pour l'installation : "Installer le package depuis des fichiers zip" pour R ou "Install from: package archive file" depuis Rstudio)
Package Rarity pour calculer des indices de rareté
Le package Rarity permettant de calculer les indices de rareté pour espèces et assemblages d'espèces est disponible sur le Comprehensive R Archive Network.
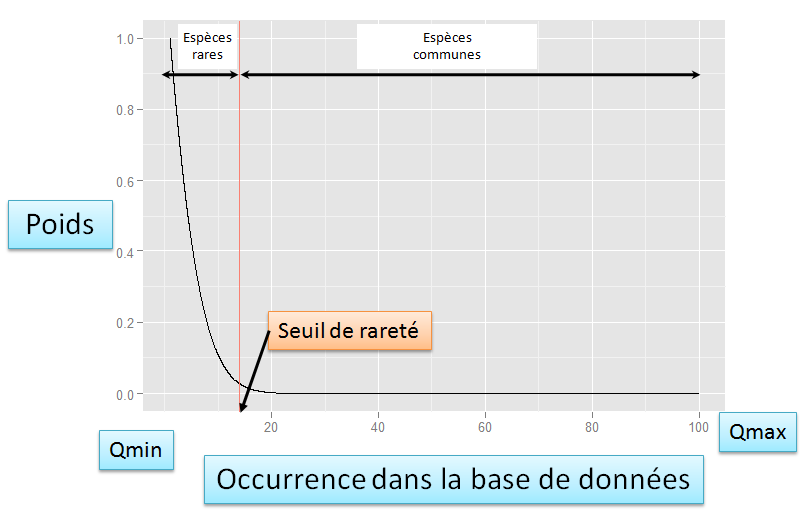
Ce package permet de calculer facilement les nouveaux indices qui intègrent le seuil de rareté ; cette flexibilité permet de les adapter quelque soit le taxon, la zone géographique et/ou l'échelle spatiale auxquels on travaille, c'est-à-dire à la base de donnée sur laquelle on travaille. Voir la section indices de rareté pour plus de détails et des exemples.
Le package requiert simplement les données d'occurrence des espèces pour pouvoir calculer les poids de rareté, et les données en présence-absence ou en abondance par site/assemblage/communauté pour pouvoir calculer les indices de rareté des sites/assemblages/communautés.
Le package Rarity intègre deux fonctions majeures :
- rWeights - Cette fonction permet de calculer les poids de rareté pour les espèces en intégrant le seuil de rareté. Des poids de rareté multi-échelles peuvent être calculés avec cette fonction. Elle permet également de calculer des poids de rareté avec des méthodes plus classiques (par exemple l'inverse de l'occurrence).
- Irr - Cette fonction permet de calculer des indices de rareté pour assemblages d'espèces, sur la base des poids de rareté.
Une présentation en PDF avec des exemples d'utilisation du package est diponible sur ce lien : rarity-package
Références