Indices de rareté
L’Indice de Rareté Relative est une évaluation de la rareté à l’échelle des communautés proposée pour améliorer les méthodes existantes en intégrant les concepts biogéographiques fondamentaux sur la rareté. Cette « mesure » de la rareté inclut un paramètre variable, le seuil de rareté, ce qui la rend adaptable quelque soit le taxon, l’échelle spatiale ou la zone géographique considérés.
Le seuil de rareté est ici défini comme le seuil d’occurrence en dessous duquel on considère les espèces comme étant rares.
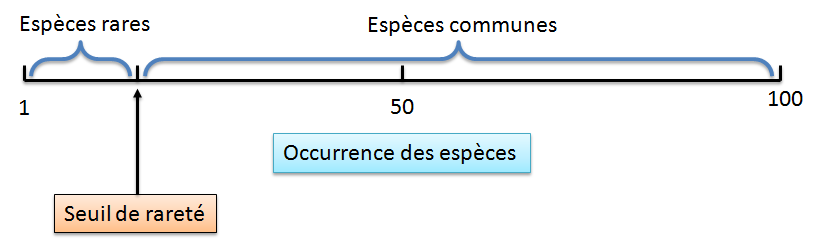
Le principe de calcul est le suivant : pour chaque espèce, on calcule un poids de rareté en fonction de l’occurrence de l’espèce, qui provient d’une base de données biodiversité.
Ensuite, pour chaque communauté identifiée, on calcule un indice basée sur la moyenne des poids de rareté des espèces de la communauté.
Cliquez sur les bandeaux pour plus d’information.
Poids de rareté
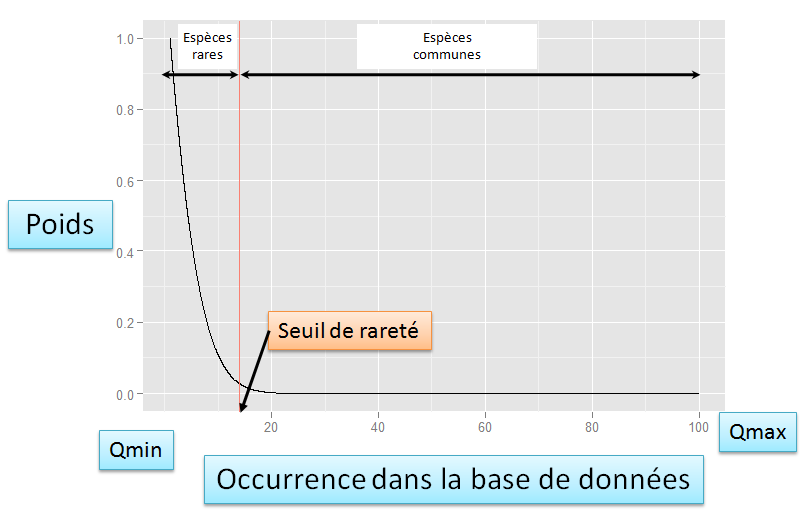
L’intégration du seuil de rareté intervient à ce stade du calcul : l’attribution des poids de rareté dépend du seuil de rareté choisi. Le poids des espèces augmente exponentiellement sous le seuil de rareté de sorte que plus l’espèce est rare, plus son poids est élevé (voir figure ci-dessous). Au delà du seuil de rareté, le poids décroît jusqu’à atteindre une valeur nulle.
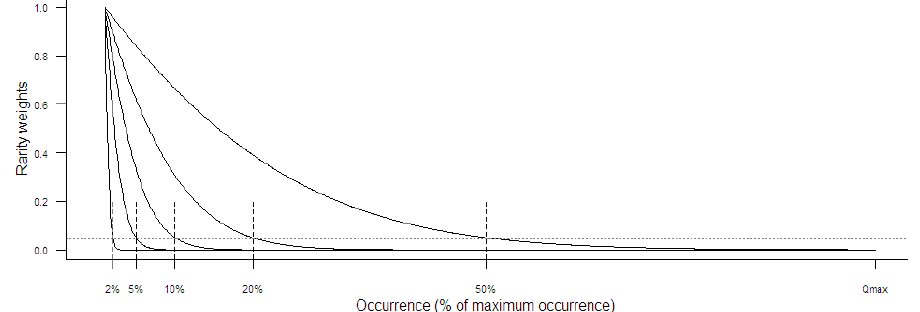
La courbe peut être ajustée en fonction du seuil de rareté choisi. Dans l’exemple ci-dessous, 5 courbes d’attribution des poids ont été ajustées suivant 5 seuils de rareté différents (chaque seuil de rareté étant défini par rapport à l’occurrence maximale, i.e., l’occurrence de l’espèce la plus répandue).
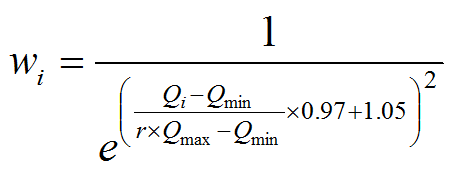
La formule d’attribution des poids a été développée, comparée avec des méthodes classiques telles que l’inverse de l’occurrence (Leroy et al. 2012), puis améliorée et publiée dans un package pour R (Leroy et al. 2013).
Calcul de l’Indice de Rareté Relative
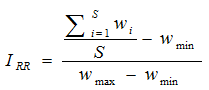
Une fois que les poids de rareté ont été calculés pour chaque espèce, l’Indice de Rareté Relative d’un assemblage d’espèce est alors simplement calculé par la somme des poids des espèces de l’assemblage, divisée par la richesse spécifique, puis normée entre 0 et 1.
Intégration de plusieurs échelles spatiales
La flexibilité de l’Indice de Rareté Relative a permis d’intégrer de manière pertinente plusieurs échelles spatiales en couplant les données d’occurrence provenant de différentes bases de données (Leroy et al. 2013).
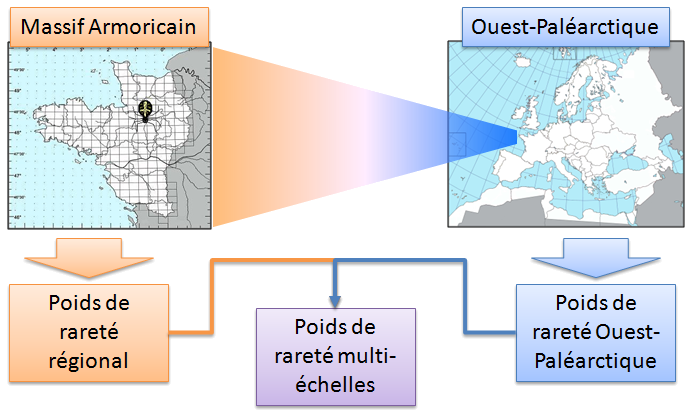
La pertinence de cette approche multi-échelle vient de l’utilisation de seuils de rareté « échelle-dépendants », c’est-à-dire de l’utilisation d’un seuil adapté à chacune des échelles considérées. Cette approche originale a permis de mettre en évidence différents types de rareté au sein des assemblages (espèces rares à toutes les échelles, espèces rares à l’échelle régionale seulement, etc.).
Indice de Rareté multi-taxons
Sur le même principe, un indice de rareté multi-taxons pertinent a pu être développé et a été utilisé pour évaluer la rareté des assemblages d’invertébrés des fonds subtidaux rocheux du littoral Breton. La pertinence de cet indice multi-taxons vient de l’utilisation de seuils de rareté « taxons-dépendants ».

[…] Indices de rareté […]