
Everybody knows Schrödinger’s cat.
That famous cat that would be both dead and alive according to a quantic model.
We can make an analogy with predictions of climate change impacts on species distributions. Most of these predictions were done using species distribution models (SDMs). The problem is that SDMs are rather uncertain techniques.
A small technical definition
Technically, SDMs consist in correlating the occurrence of a species (i.e., places where it has been found) to environmental variables (e.g., the climate in those places). With this we can assume the relationship between the species and its environment, and then extrapolate in space, to see where the environment is suitable for species presence; and in time, for example to predict future climate change impacts on the species.
First, there are numerous different modelling techniques (‘GLM’, ‘GAM’, ‘MaxEnt’, ‘BRT’, etc.); each with its own underlying assumptions and parametrisations. These different techniques often give varying results, sometimes divergent. In addition, there are numerous protocols in the literature: based on presence-absence data, presence-only data with pseudo-absence sampling, cross-validation, etc.
Environmental variables must also be carefully chosen, for they need to be relevant to the species. When the species’ ecology is well known, it can be easy, but when it’s not, then we try to identify them using a variable selection protocol. Different selected variables will provide different results.
Furthermore, to make future predictions, we have to use future scenarios, which are by essence uncertain. And for each scenario, there are numerous climate models, each trying to represent in its own way the future climate for the considered scenario. Climate models have varying performances, each one being stronger on some regions of the globe and weaker in others. As expected, different climate models will provide different predictions for a same scenario.
And I omitted talking about occurrence data of the modelled species: according to their quantity and quality (or their biases), their results will also be different.
How to choose the correct model?
We could use model evaluation techniques to try and find the best model. However, these techniques rarely provide an accurate evaluation of models (I won’t expand on that here, it may be the subject of a future article). Hence, in general evaluation techniques cannot be used to find reliable predictions; they can only be used to identify unreliable predictions. In other words: a bad evaluation means that the prediction is probably very bad; but a good evaluation does not mean that the prediction is accurate.
An appropriate approach consists in using “Ensemble Modelling” approaches, i.e. making many predictions with different techniques, protocols and climate models., and then use the average or median prediction. Different works showed that this average prediction provided better results; but the real strength of ensemble modelling is to show the variability of predictions. If all the predictions are similar, they are much more reliable than diverging ones!
Schrödinger Distribution Models
However, if we dare looking at all the predictions in our ensemble modelling, it is not uncommon to obtain Schrödinger Distribution Models, with the same species being predicted to become both extinct (-100% in range size) and super-expand its distribution range (e.g., +200% range size).

These Schrödinger Distribution Models pose two questions:
1. Can we trust a prediction delivered without uncertainty?
2. How to use predictions worthy of Schrödinger?
1. A prediction without uncertainty is uncertain.
SDMs are uncertain, even more in the case of future predictions. For this reason, it seems mandatory to me to provide an indication of the prediction’s uncertainty. Interpreting a future prediction without an indication of uncertainty is like horoscope. Obviously, different climate change scenarios should be presented, as these are different plausible futures as identified by the IPCC. But the variability of predictions within each scenario should be presented, using and ensemble model approach.
Below is an illustration from an article we recently published on spiders. On the left hand are the average predictions from an ensemble modelling procedure; on the right, the same prediction provided with an indication of their uncertainty (the intervals are the range within which 95% of the predictions are contained). The predicted range expansion therefore ranges from +0% to +125%, whereas the predicted contraction ranges from -0% to -70%. We can therefore see that only using the average predictions means omitting most of the information.
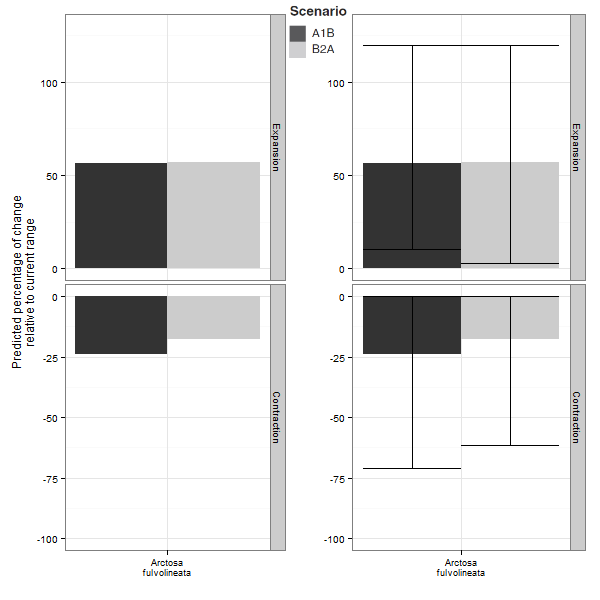
If a single prediction is used for each climate scenario, there should be a sound justification, otherwise it becomes possible to choose the only prediction that suits our expectations best…
2. An uncertain prediction can provide certitudes — or how to use predictions worthy of Schrödinger?
On the one hand, highly disagreeing models give us the certainty of the poor quality of our predictions. It leads us to ask questions about the quality of calibration, and on the reasons why the predictions are not converging. It could be a species whose distribution is in fact driven by factors too difficult to model (by SDMs), such as microscale factors, biotic factors, etc.
On the other hand, according to the study objective, it can be possible to use very divergent prediction by “extracting” model uncertainty. For example, Kujala et al. (2013) propose a robust framework to plan conservation actions on the basis of uncertain predictions. In a nutshell, the idea is to focus regions where the models agree rather than where models disagree.
For example, it is possible to calculate a probability of presence with uncertainty discounted, by subtracting from the average probability of the ensemble modelling n times the standard deviations of probabilities of the ensemble modelling. This approach comes from decision theory in the face of severe uncertainty, and to my mind it would be very beneficial if they became generalised in studies of climate change impact on biodiversity. This is what we did on spiders to identify populations to protect for a conservation program in France, in spite of significant uncertainties in the predictions for several species.
TL; DR
Species Distribution Models have inherent uncertainties which can become important in future predictions: these uncertainties should always be assessed and indicated for a proper interpretation.
Never trust a prediction provided without indication of uncertainty…
Methods exist to use SDMs in spite of severe uncertainty, and should therefore be (systematically?) applied.