La version 1.2-1 du package Rarity vient de sortir, et cette version introduit une nouvelle fonction permettant de faire des « plots de corrélation ».
Ces plots de corrélation permettent d’analyser graphiquement et rapidement la corrélation entre deux ou plus variables avec une représentation synthétique.
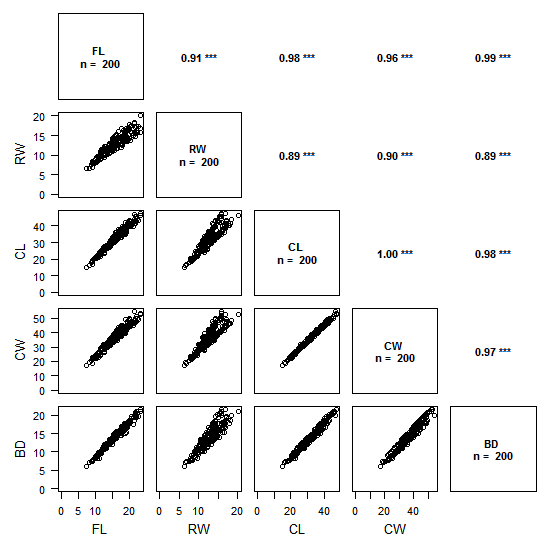
Ci-dessus un exemple avec des données de taille de crabes (package MASS).
Le graphique se décompose en deux :
- le triangle inférieur gauche présente les relations entre variables 2 à 2, de type « scatter plot »
- le triangle supérieur droit présente les valeurs de corrélations avec la méthode choisie (ci-dessus : Pearson) et le degré de significativité associé.
Le degré de significativité suit le code suivant :
p ≤ 0.001 : ‘***’
p ≤ 0.01 : ‘**’
p ≤ 0.05 : ‘*’
p ≤ 0.1 : ‘-’
La lecture se fait en croisant les variables sur le graphique comme dans la lecture d’un tableau de contingence : par exemple, le graphique tout en haut à gauche présente les valeurs de RW en fonction de FL, et en regard, de l’autre côté de la diagonale, on a la valeur du coefficient de corrélation de Pearson correspondante : 0.91, avec une significativité élevée (p < 0.001).
Pour créer cette fonction je me suis largement inspiré du graphique en Supporting Information de Kier et al. 2009 (page 3).
L’appel de la fonction est relativement simple, il faut simplement un data.frame avec les différentes variables en colonnes, préciser la méthode, et le reste est automatique. Deux méthodes sont disponibles :
- Pearson : dans ce cas les valeurs des variables sont directement affichées sur le graphique
- Spearman ou Kendall : dans ce cas les rangs des variables sont affichées, car ces méthodes sont basées sur les rangs
Voici une série d’exemples simples à 2 variables (cette fonction sera surtout utile avec plus de 2 variables).
> library(Rarity) > data(spid.occ) # Exemple avec les occurrences des araignées du Massif Armoricain > corPlot(spid.occ, method = "pearson")> corPlot(spid.occ, method = "spearman")# Avec Spearman on a le graphique des rangs des variables. Cette méthode est particulièrement appropriée lors de l'étude de la congruence entre indices.
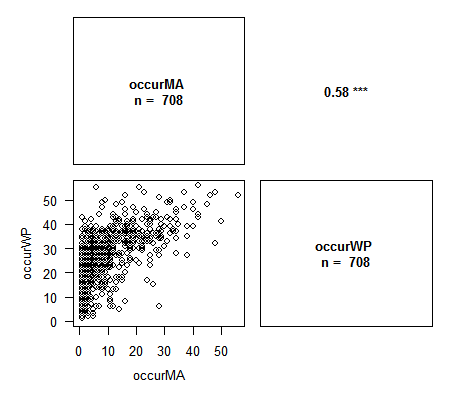
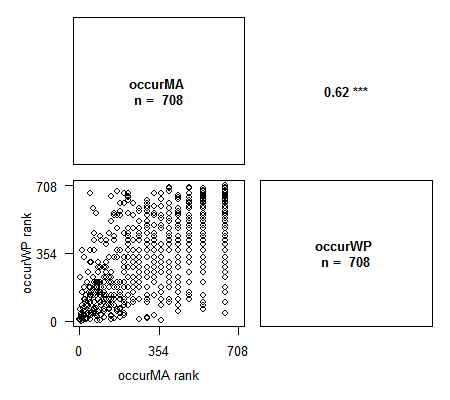
Les variables contenant des NA sont correctement gérées par la fonction. Plusieurs options pour ajuster le graphique sont disponibles : nombre de chiffres pour les valeurs de corrélation, labels des axes, traitement des NA, titre, et toutes les options graphiques habituelles pour changer le contenu des plots. N’hésitez pas à me faire des suggestions d’ajout !
> corPlot(spid.occ, method = "pearson", pch = 16, cex = .5, digits = 3, xlab = c("Occurrence régionale", "Occurrence ouest Paléarctique"), ylab = c("Occurrence régionale", "Occurrence ouest Paléarctique"), col = "#94B62D")
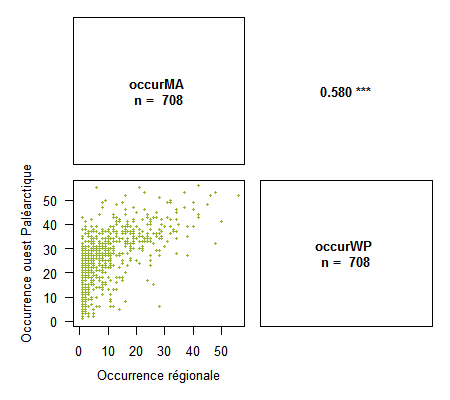
Merci à Ivailo Stoyanov pour ses conseils sur l’amélioration de cette fonction.
– edit-Corrigé et à jour sur le CRAN !
Un petit bug s’est glissé dans la version 1.2 du package et lorsque la méthode de Pearson est utilisée, le graphique partira toujours de 0. Ce bug a été corrigé et sera inclus dans la prochaine version du package !
En attendant la mise à jour sur le CRAN, voici la version corrigée : Rarity_1.2-1 (zip) ou Rarity_1.2-1.tar.gz (Pour l’installation : « Installer le package depuis des fichiers zip » pour R ou « Install from: package archive file » depuis Rstudio)